The New QA Pyramid: Building Agentic Test Strategies from Scratch
Testing isn’t what it used to be.
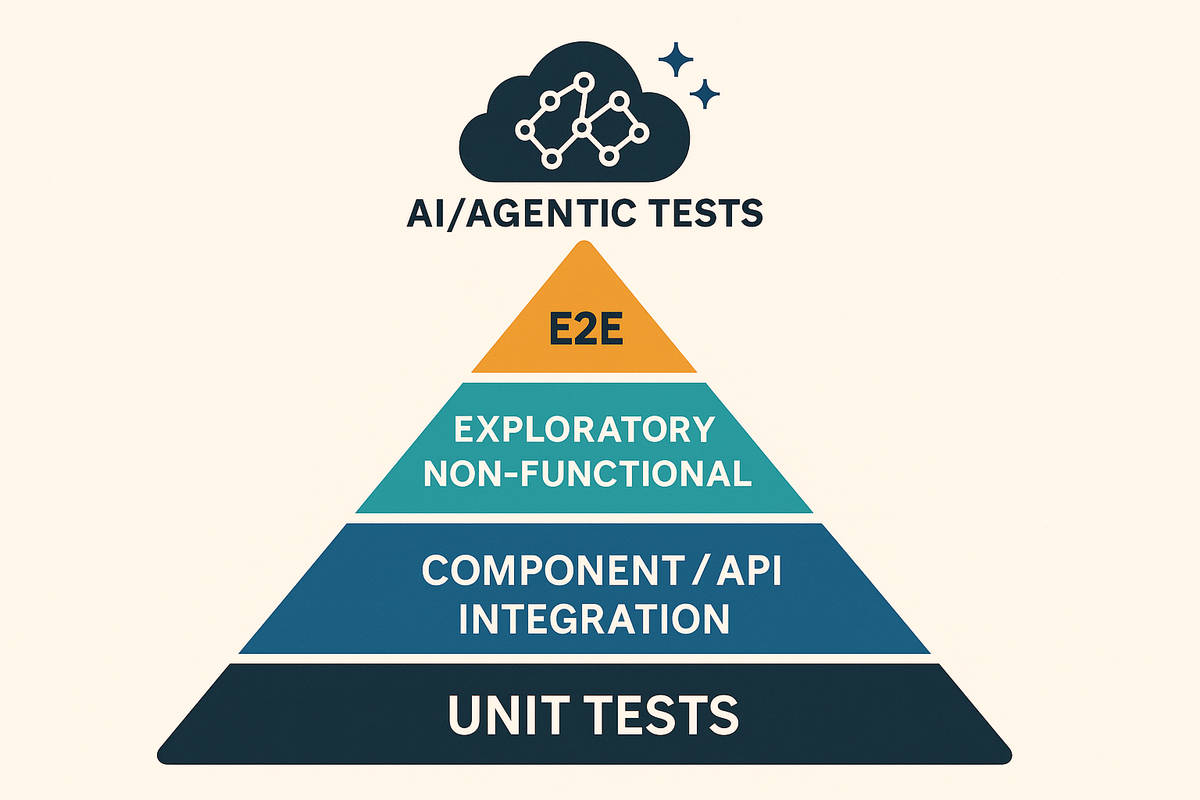
The old test pyramid; unit, integration, E2E; still matters. But it’s no longer enough.
Modern software is intelligent. It generates content, reasons, adapts, and learns. That means QA isn’t just about checking if a button works anymore. It’s about evaluating outputs, behavior, reasoning, and user intent.
In this post, we’ll walk through:
- The new QA pyramid for AI-native and AI-powered teams
- How to start from scratch or evolve your existing practice
- Where AI fits in (and how to use it safely)
- How to layer in agentic QA practices step by step
The New QA Pyramid (Two Sides of the Same Triangle)
We now need to think of QA in two simultaneous dimensions:
1. AI in QA (AI-powered testing workflows)
- LLM-generated test cases
- AI-powered triage and flake detection
- Self-healing pipelines
- Change impact-based regression selection
2. QA for AI (Testing AI systems themselves)
- LLM-as-a-Judge (LaaJ)
- RAG evaluation (faithfulness, relevance)
- Scoring hallucinations
- Prompt regression
We’re not just testing applications anymore. We’re testing intelligence.
Start With Where You Are
Here’s how to approach the journey depending on your maturity stage:
Ground Zero / MVP Stage
- Write manual test cases for critical flows
- Set up basic Postman or PyTest API checks
- Use GPT to help draft test cases based on Jira tickets
- Optional: try a test generator agent to convert Figma + Jira → Playwright skeletons
Series A / 0–1 Startup Stage
- Add Playwright E2E for core flows
- Start versioning tests + results in Allure
- Use AI to:
- Generate edge cases
- Summarize test sessions
- Identify redundant or missing tests
- Try LLM-as-a-Judge to evaluate non-deterministic UI or form output
Mature Team w/ Traditional QA But No AI
- Add AI-based flake clustering and failure summaries
- Introduce self-healing retries (agent rewrites selector, re-runs)
- Build a regression selector that uses PR diff + test metadata
- Let GPT flag orphaned manual cases or non-tagged automation
Teams Testing AI/LLM Products
- Evaluate using LLM-as-a-Judge
- Use RAGAS or DeepEval for LLM output validation
- Store reasoning traces (e.g., CoT paths, tool usage) for regression
- Score outputs for hallucination, coherence, faithfulness
Layer-by-Layer: The Modern QA Pyramid
| Layer | Test Types | AI Powerups |
|---|---|---|
| Intelligence Layer | LLM-as-a-Judge, Prompt Regression | GPT scoring, RAG eval, response embedding similarity |
| Non-Functional | Perf, a11y, security | AI-assisted a11y sweeps, log analysis, threat detection |
| UI / UX | E2E, exploratory | Visual diffing, dynamic test selection, flake detection |
| Application Logic | Unit, Component | GPT-generated unit tests, snapshot creation |
| Services & APIs | API, Integration | Postman + LLM for contract inference, gap checks |
| Infra / CI/CD | Healthchecks, smoke | Self-healing, retry orchestration, agentic rerun pipeline |
Agentic QA is not replacing traditional QA. It’s enhancing it—layer by layer.
Example: Evolving a “Schedule Visit” Flow
| Stage | Traditional | Agentic Add-on |
| Manual | Write test case in Zephyr | Ask GPT to expand scenarios using design + PRD |
| Automation | Write Playwright test | GPT generates test scaffolds, retries, logs selectors |
| CI/CD | Run tests nightly | Self-healing agent retries failed tests with selector fix |
| Reporting | Allure dashboards | GPT agent posts coverage gap + flaky summary to Slack |
| Output QA | Check confirmation screen | LLM-as-a-Judge scores the wording + layout accuracy |
What About Security?
If you’re in healthcare, fintech, or other regulated industries, don’t skip this:
Safe AI in QA:
- Only test in non-prod environments
- Obfuscate PHI/PII before sending to LLMs
- Use local models or RAG with in-house data for GenAI
- Log and version AI output + final test artifacts
Don’t:
- Don’t copy-paste production user data into GPT
- Don’t blindly accept AI-generated tests without review
- Don’t give LLMs write access to prod systems (even test agents)
How to Start: A Step-by-Step Plan
- Map what you have: Manual, automation, flaky areas, coverage gaps
- Pick one test case and try:
- GPT-generated test
- AI-assisted triage of a failure
- LLM-as-a-Judge output scoring
- Add metadata to your tests (tags, Jira IDs, coverage level)
- Introduce dashboards that combine manual + auto + AI QA insight
- Automate triage + self-healing agents (CI/CD + Slack reporting)
- Review results weekly: accuracy, gaps, false positives
- Scale what works. Cut what doesn’t.
QA in the AI Future
This is how you build QA that keeps up with the AI-native future:
- Layer traditional testing with intelligent agents
- Treat outputs as evaluations, not just pass/fail assertions
- Secure your pipelines, but don’t be afraid to experiment
You don’t need 100% coverage. You need 100% visibility and confidence—and that comes from layering the right types of tests with the right kinds of intelligence.
Start with one layer. Add another. Iterate. The pyramid will build itself.
👉 Want more posts like this? Subscribe and get the next one straight to your inbox. Subscribe to the Blog or Follow me on LinkedIn


Comments ()