Prompt Regression Testing 101: How to Keep Your LLM Apps from Quietly Breaking
When we talk about testing, most people think of unit tests, integration tests, and end-to-end tests. But if you’re working with large language models (LLMs), there’s a new kind of test you can’t ignore: prompt regression testing.
It sounds fancy, but at its core it’s just this: making sure that changes to your prompts, models, retrieval corpus, or parameters don’t accidentally make your app worse. Just like traditional regression testing protects software logic, prompt regression testing protects the fragile chain of prompt + model + context that powers your LLM system.
Without it, you’re flying blind. You upgrade a model, tweak a system prompt, or refresh your RAG index; and suddenly customer queries that worked yesterday are failing today.
This post is your Prompt Regression Testing 101. We’ll cover what it is, why it matters, and how to set it up step by step.
What Is Prompt Regression Testing?
Prompt regression testing is a QA discipline for LLM apps. The goal is simple:
Catch regressions in quality before they hit production.
That means every time you change something; a prompt, a model version, a RAG index, even a tool integration; you run a battery of tests that simulate real user tasks.
Each test checks multiple dimensions:
- Deterministic checks: exact matches, regex validation, JSON schema compliance.
- Semantic checks: meaning equivalence, embedding similarity, fact coverage.
- Judge-based checks: another LLM acts as evaluator, scoring correctness, completeness, tone.
- Non-functional checks: latency, token usage, cost, refusal rate, jailbreak resistance.
And because LLM apps are non-deterministic, you don’t rely on one check alone. You layer them, like filters, so you can catch brittle failures fast and let nuanced scoring handle the rest.
The outcome is a versioned report that tells you: what passed, what failed, and whether your latest change improved or degraded the system.
Why Do We Need It?
Here’s the painful reality: LLMs are unstable baselines.
- Vendors silently update models.
- Retrieval indexes drift as data changes.
- Prompts evolve as product teams tune behavior.
- Temperature and decoding tweaks change outputs.
Without regression tests, you only find out about regressions when customers complain; or worse, when you violate safety/compliance requirements.
Prompt regression testing gives you a safety net and a time machine:
- Safety net → you block bad merges before they ship.
- Time machine → you can see exactly when and why something broke.
For a healthcare bot, that might mean catching the day your AWV eligibility prompt stopped including required disclaimers. For a finance assistant, it could be spotting when a jailbreak slipped past your guardrails.
The Building Blocks of Prompt Regression Testing
Let’s break down the main pieces.
1. A Versioned Test Suite of Real Tasks
Think of this as your “unit tests” for LLM prompts. You create a set of 20–100 tasks that mirror your critical user journeys; the things customers actually do.
Example (healthcare app):
- “Is G0136 billable during an AWV?”
- “Schedule a follow-up appointment.”
- “Explain AWV in 3 bullet points.”
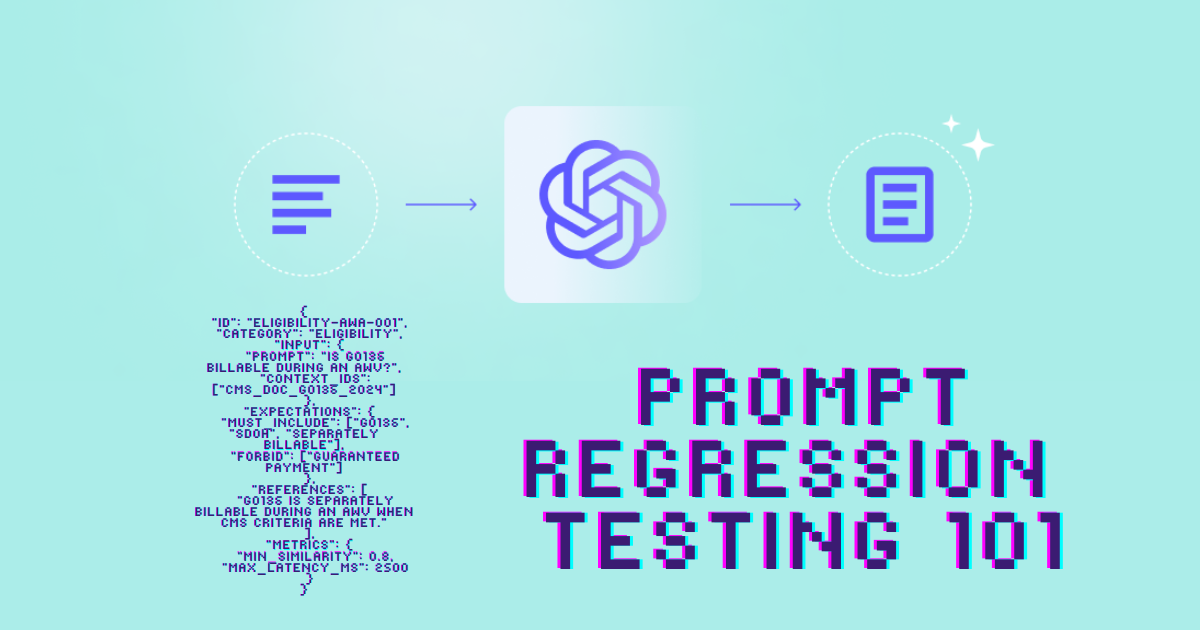
Each test is stored as structured data (JSON/CSV), with:
- An ID
- A category (eligibility, billing, safety)
- An input (prompt + optional context)
- Expectations (must include, forbid, references)
- Metrics (min similarity, max latency, cost thresholds)
These tests are versioned in Git so you can track how your suite evolves over time. Anytime you see a regression in production, you add it back into the suite; so it never slips again.
2. Multi-Layer Checks
Each test runs through multiple checks:
- Deterministic checks → fast, binary rules like “must contain G0136” or “valid JSON schema.”
- Semantic checks → embedding similarity, key fact coverage. Good for open-ended answers.
- Judge-based checks → an LLM-as-a-Judge scoring answers on rubrics like correctness, faithfulness, completeness, tone.
- Non-functional checks → latency under 2.5s, token budget, cost, refusal rate, jailbreak resistance.
Example:
Reference: “Symptoms of type 2 diabetes: thirst, urination, fatigue.”
Output: “You feel tired, very thirsty, and need to pee often.”
- Exact match? Fail.
- Semantic similarity? Pass (≥0.85).
- Key fact coverage? All 3 present. ✅
3. Run Reports & Trend Charts
Every run produces a structured report with:
- Which tests passed or failed.
- Scores across dimensions.
- Comparison to previous runs.
You set pass/fail gates:
- “Overall pass ≥90%”
- “No safety fails”
- “p95 latency ≤ 2.5s”
CI/CD enforces these gates. If a change makes your bot worse, the merge is blocked.
And because runs are versioned, you can also see trends over time: accuracy up or down, latency creeping up, costs rising, refusal rate spiking.
What to Test (Categories)
When building your suite, cover these common categories:
- Correctness → Closed tasks (math, eligibility) and open tasks (summaries, advice).
- Format & structure → JSON, SQL, markdown, API schemas.
- Groundedness for RAG → answers must stick to retrieved docs.
- Safety → no PII leaks, proper disclaimers, resistant to jailbreaks.
- Style & constraints → tone, length, format requirements.
- Function/tool use → correct tool calls with valid arguments.
- Non-functional → latency, cost, token budgets.
How It Works (Conceptual Flow)
- Freeze the contract → define what “good” means: rubrics, thresholds, prompt versions.
- Curate datasets → golden paths, edge cases, adversarial prompts.
- Record ground truth → exact outputs or criteria for open-ended tasks.
- Lock the environment → pin model, params, RAG index snapshot.
- Run the harness → a test runner that simulates production calls.
- Score & gate → enforce thresholds in CI/CD.
- Track over time → dashboards for accuracy, latency, cost, safety.
Step-by-Step Implementation
Here’s how to go from zero to a working system:
Step 1: Define Critical User Journeys
Pull 2–4 weeks of logs. Rank intents by volume × business impact × risk.
Create 20–100 test tasks covering 80% of your traffic, plus high-risk cases.
Step 2: Design Rubrics
Write down the rules for “good.” Start with:
- Correctness (0–3)
- Faithfulness (0–3)
- Completeness (0–3)
- Format (pass/fail)
Step 3: Choose Scorers
Layer them: deterministic → semantic → judge.
Cheap failures get caught early; nuanced checks catch the rest.
Step 4: Version Everything
Store configs with each run: prompt version, model ID, params, RAG snapshot hash.
Step 5: Build the Harness
A simple CLI runner that:
- Loads test cases.
- Calls your app like production.
- Collects outputs, timings, token usage.
- Runs all scorers.
- Emits a JSON/HTML report.
Step 6: Gate Your CI
Add a workflow that runs on every pull request. Block merges if pass rate <90% or safety fails >0.
Step 7: Observe
Persist every run to a database. Build dashboards for trends. Add alerts for sudden drops.
Step 8: Expand Datasets
Mine production logs for new regressions. Convert them into tests. Refresh your suite monthly.
Step 9: Periodic Audits
Re-grade with different judge models. Run human spot checks. Update rubrics and thresholds.
Step 10: Upgrade Safely
When testing new models or prompts, run A/B across your full suite. Compare metrics before rolling out.
Practical Defaults
- Suite size: start with 40–60, grow to 150–300.
- Params: test with temperature=0.0, seed=42.
- Semantic threshold: start at 0.80.
- Judge models: smaller, cheaper model daily; bigger one for audits.
- Safety: zero tolerance for dangerous outputs.
- RAG pinning: log doc IDs, chunking, embedder ID.
- Cost control: cap tokens, truncate long contexts.
Suggested Repo Layout
/eval
/tests/ # *.jsonl test datasets
/rubrics/ # rubrics + judge prompts
/scorers/ # deterministic.py, semantic.py, judge.py
/configs/ # manifests for each run
/storage/ # results storage schema
/reporters/ # html/csv reporters
audits/ # audit notes
ab/ # A/B runs
harness.py
cli.py
gates.yaml
.github/workflows/prompt-regression.yml
The Payoff
Prompt regression testing might sound like overhead. But once you have it, it becomes one of your highest-leverage quality practices.
- You can upgrade models with confidence.
- You can prove to stakeholders that quality is stable.
- You can stop regressions before customers ever see them.
In other words: it’s unit testing for the LLM era.
If you’re building with LLMs, you can’t afford not to have it.
Next Steps:
- Start small with 20–40 test cases.
- Add rubrics and scorers.
- Build a harness and hook it to CI.
- Grow your suite with every regression you catch.
Prompt regression testing isn’t flaky when done right. It’s the foundation for shipping reliable, trustworthy AI products.
👉 Want more posts like this? Subscribe and get the next one straight to your inbox. Subscribe to the Blog or Follow me on LinkedIn



Comments ()